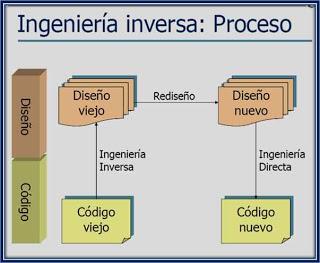
El objetivo de la ingeniería inversa es obtener información o un diseño a partir de un producto accesible al público, con el fin de determinar de qué está hecho, qué lo hace funcionar y cómo fue fabricado.
Hoy en día (principios del siglo XXI), los productos más comúnmente sometidos a ingeniería inversa son los programas de computadoras y los componentes electrónicos, pero, en realidad, cualquier producto puede ser objeto de un análisis de Ingeniería Inversa.
En el caso concreto del software, se conoce por ingeniería inversa a la actividad que se ocupa de descubrir cómo funciona un programa, función o característica de cuyo código fuente no se dispone, hasta el punto de poder modificar ese código o generar código propio que cumpla las mismas funciones.
La ingeniería inversa nace en el transcurso de la Segunda Guerra Mundial, cuando los ejércitos enemigos incautaban insumos de guerra como aviones u otra maquinaria de guerra para mejorar las suyas mediante un exhaustivo análisis.
Definición de Ingeniería inversa
El método se denomina así porque avanza en dirección opuesta a las tareas habituales de ingeniería, que consisten en utilizar datos técnicos para elaborar un producto determinado. En general, si el producto u otro material que fue sometido a la ingeniería inversa fue obtenido en forma apropiada, entonces el proceso es legítimo y legal. De la misma forma, pueden fabricarse y distribuirse, legalmente, los productos genéricos creados a partir de la información obtenida de la ingeniería inversa, como es el caso de algunos proyectos de Software libre ampliamente conocidos.
El programa Samba es un claro ejemplo de ingeniería inversa, dado que permite a sistemas operativos UNIX compartir archivos con sistemas Microsoft Windows. El proyecto Samba tuvo que investigar información confidencial (no liberada al público en general por Microsoft) sobre los aspectos técnicos relacionados con el sistema de archivos Windows. Lo mismo realiza el proyecto WINE para el conjunto de API de Windows y OpenOffice.org con los formatos propios de Microsoft Office, o se hace para entender la estructura del sistema de archivos NTFS y así poder desarrollar drivers para la lectura-escritura sobre el mismo (principalmente para sistemas basados en GNU/Linux).
La ingeniería inversa es un método de resolución. Aplicar ingeniería inversa a algo supone profundizar en el estudio de su funcionamiento, hasta el punto de que podamos llegar a entender, modificar y mejorar dicho modo de funcionamiento.
Pero este término no sólo se aplica al software, sino que también se considera ingeniería inversa el estudio de todo tipo de elementos (por ejemplo, equipos electrónicos, microcontroladores, u objeto fabril de cualquier clase). Diríamos, más bien, que la ingeniería inversa antecede al nacimiento del software, tratándose de una posibilidad a disposición de las empresas para la producción de bienes mediante copiado1 desde el mismo surgimiento de la ingeniería.
¿Por qué se llama Ingeniería Inversa?
1- Objetivos y medios contrarios:
– INGENIERIA: Desarrollo de un producto a partir de unas especificaciones dadas, usando para ello los recursos disponibles.
– ING. INVERSA: A partir de un producto se realiza la deducción de las especificaciones que cumple y los recursos usados para ello.
2- Proceso de implementación invertido:
– INGENIERIA: De lo concreto a lo abstracto.
– ING. INVERSA: De lo abstracto a lo concreto.
Usos de la ingeniería inversa
* La ingeniería inversa suele ser empleada por empresas, para analizar si el producto de su competencia infringe patentes de sus propios productos.
* Muchas veces, la ingeniería inversa es utilizada en el área militar para investigar (y copiar) las tecnologías de otras naciones, sin obtener planos ni detalles de su construcción o desarrollo.
* En el software y en el hardware, la ingeniería inversa, muchas veces es empleada para desarrollar productos que sean compatibles con otros productos, sin conocer detalles de desarrollo de éstos últimos. En otras palabras, quien desarrolla los nuevos productos, no puede acceder a los detalles de fabricación de los productos de los que intenta ser compatibles.
* La ingeniería inversa también es empleada para comprobar la seguridad de un producto, generar keygens de aplicaciones, reparación de productos, etc.
Motivación
Ilícitas:
– Apropiación tecnológica.
– Económica (explotación de los resultados).
Licitas:
– Sustitución de componentes obsoletos.
– Auditoria de seguridad.
– Comprobar respeto de patentes y licencias.
Ingeniería inversa del Software
La ingeniería inversa de software es un tipo de ingeniería inversa dedicada a las aplicaciones.
La ingeniería inversa en software significa descubrir qué hace el software sin tener el código fuente programado del mismo. Es una tarea que, en general, es complicada.
Suele emplearse con fines de aprendizaje, diagnóstico de software, análisis de seguridad y pirateo de programas.
Beneficios de Ingeniería Inversa del Software
La aplicación de ingeniería inversa nunca cambia la funcionalidad del software sino que permite obtener productos que indican cómo se ha construido el mismo. Se realiza permite obtener los siguientes beneficios:
– Reducir la complejidad del sistema: al intentar comprender el software se facilita su mantenimiento y la complejidad existente disminuye.
– Generar diferentes alternativas: del punto de partida del proceso, principalmente código fuente, se generan representaciones gráficas lo que facilita su comprensión.
– Recuperar y/o actualizar la información perdida (cambios que no se documentaron en su momento): en la evolución del sistema se realizan cambios que no se suele actualizar en las representaciones de nivel de abstracción más alto, para lo cual se utiliza la recuperación de diseño.
– Detectar efectos laterales: los cambios que se puedan realizar en un sistema puede conducirnos a que surjan efectos no deseados, esta serie de anomalías puede ser detectados por la ingeniería inversa.
– Facilitar la reutilización: por medio de la ingeniería inversa se pueden detectar componentes de posible reutilización de sistemas existentes, pudiendo aumentar la productividad, reducir los costes y los riesgos de mantenimiento.
La finalidad de la ingeniería inversa es la de desentrañar los misterios y secretos de los sistemas en uso a partir del código. Para ello, se emplean una serie de herramientas que extraen información de los datos, procedimientos y arquitectura del sistema existente.
Tipos de Ingeniería Inversa del Software
1- Ingeniería inversa de datos
La ingeniería inversa de datos suele producirse a diferentes niveles de abstracción. En el nivel de programa, es frecuente que sea preciso realizar una ingeniería inversa de las estructuras de datos internas del programa, como parte del esfuerzo general de la reingeniería.
En el nivel del sistema, es frecuente que se efectúe una reingeniería de las estructuras globales de datos (por ejemplo: archivos, bases de datos) para ajustarlas a los paradigmas nuevos de gestión de bases de datos (por ejemplo, la transferencia de archivos planos a unos sistemas de bases de datos relacionales u orientados a objetos).
La ingeniería inversa de las estructuras de datos globales actuales establecen el escenario para la introducción de una nueva base de datos que abarque todo el sistema.
Estructuras de datos internas. Las técnicas de ingeniería inversa para datos de programa internos se centran en la definición de clases de objetos5. Esto se logra examinando el código del programa en un intento de agrupar variables de programa que estén relacionadas.
En muchos casos, la organización de datos en el seno el código identifica los tipos abstractos de datos. Por ejemplo, las estructuras de registros, los archivos, las listas y otras estructuras de datos que suelen proporcionar una indicación inicial de las clases.
Para la ingeniería inversa de clases, se sugiere el enfoque siguiente:
– Identificación de los indicadores y estructuras de datos locales dentro del programa que registran información importante acerca de las estructuras de datos globales (por ejemplo, archivos o bases de datos).
– Definición de la relación entre indicadores y estructuras de datos locales y las estructuras de datos globales. Por ejemplo, se podrá activar un indicador cuando un archivo esté vacío; una estructura de datos local podrá servir como memoria intermedia de los cien últimos registros recogidos para una base de datos central.
– Para toda variable (dentro de un programa) que represente una matriz o archivo, la construcción de un listado de todas las variables que tengan una relación lógica con ella.
Estos pasos hacen posible que el ingeniero del software identifique las clases del programa que interactúan con las estructuras de datos globales.
Estructuras de bases de datos. Independientemente de su organización lógica y de su estructura física, las bases de datos permiten definir objetos de datos, y apoyan los métodos de establecer relaciones entre objetos.
Por tanto, la reingeniería de un esquema de bases de datos para formar otro exige comprender los objetos ya existentes y sus relaciones.
Para definir el modelo de datos existente como precursor para una reingeniería que producirá un nuevo modelo de base de datos se pueden emplear los pasos siguientes:
1- Construcción de un modelo de objetos inicial. Las claves definidas como parte del modelo se podrán conseguir mediante la revisión de registros de una base de datos de archivos planos o de tablas de un esquema relacional. Los elementos de esos registros o tablas pasarán a ser atributos de una clase.
2- Determinación de los candidatos a claves. Los atributos se examinan para determinar si se van a utilizar o no para señalar a otro registro o tabla. Aquellos que sirvan como punteros pasarán a ser candidatos a claves.
3- Refinamiento de las clases provisionales. Se determina si ciertas clases similares pueden o no combinarse dentro de una Única clase.
4- Definición de las generalizaciones. Para determinar si se debe o no construir una jerarquía de clases con una clase de generalización como precursor de todos sus descendentes se examinan las clases que pueden tener muchos atributos similares.
5- Descubrimiento de las asociaciones. Mediante el uso de técnicas análogas al enfoque de CRC se establecen las asociaciones entre clases.
Una vez que se conoce la información definida en los pasos anteriores, se pueden aplicar una serie de transformaciones para hacer corresponder la estructura de la vieja base de datos con una nueva estructura de base de datos.
2- Ingeniería inversa de lógica o de proceso:
La primera actividad real de la ingeniería inversa comienza con un intento de comprender y posteriormente, extraer las abstracciones de procedimientos representadas por el código fuente. Para comprender las abstracciones de procedimientos, se analiza el código en distintos niveles de abstracción: sistema, programa, componente, configuración y sentencia.
Antes de iniciar el trabajo de ingeniería inversa detallado debe comprenderse totalmente la funcionalidad general de todo el sistema de aplicaciones sobre el que se está operando. Esto es lo que establece un contexto para un análisis posterior, y proporciona ideas generales acerca de los problemas de interoperabilidad entre aplicaciones dentro del sistema. Así pues, cada uno de los programas de que consta el sistema de aplicaciones representará una abstracción funcional con un elevado nivel de detalle, creándose un diagrama de bloques como representación de la iteración entre estas abstracciones funcionales. Cada uno de los componentes de estos diagramas efectúa una subfunción, y representa una abstracción definida de procedimientos. En cada componente se crea una narrativa de procesamientos. En algunas situaciones ya existen especificaciones de sistema, programa y componente. Cuando ocurre tal cosa, se revisan las especificaciones para preciar si se ajustan al código existente, descartando posibles errores.
Todo se complica cuando se considera el código que reside en el interior del componente. El ingeniero busca las secciones del código que representan las configuraciones genéricas de procedimientos. En casi todos los componentes, existe una sección de código que prepara los datos para su procesamiento (dentro del componente), una sección diferente de código que efectúa el procesamiento y otra sección de código que prepara los resultados del procesamiento para exportarlos de ese componente. En el interior de cada una de estas secciones, se encuentran configuraciones más pequeñas. Por ejemplo, suele producirse una verificación de los datos y una comprobación de los límites dentro de la sección de código que prepara los datos para su procesamiento.
Para los sistemas grandes, la ingeniería inversa suele efectuarse mediante el uso de un enfoque semiautomatizado. Las herramientas CASE se utilizan para “analizar” la semántica del código existente. La salida de este proceso se pasa entonces a unas herramientas de reestructuración y de ingeniería directa que completarán el proceso de reingeniería.
Cuándo aplicar ingeniería inversa de procesos
Cuando la ingeniería inversa se aplica sobre código de un programa para averiguar su lógica o sobre cualquier documento de diseño para obtener documentos de análisis o de requisitos se habla de ingeniería inversa de procesos.
Habitualmente, este tipo de ingeniería inversa se usa para:
– Entender mejor la aplicación y regenerar el código.
– Migrar la aplicación a un nuevo sistema operativo.
– Generar/completar la documentación.
– Comprobar que el código cumple las especificaciones de diseño.
La información extraída son las especificaciones de diseño: se crean modelos de flujo de control, diagramas de diseño, documentos de especificación de diseño, etc. y pudiendo tomar estas especificaciones como nuevo punto de partida para aplicar ingeniería inversa y obtener información a mayor nivel de abstracción.
¿Cómo hacemos la ingeniería inversa de procesos?
A la hora de realizar ingeniería inversa de procesos se suelen seguir los siguientes pasos:
– Buscamos el programa principal.
– Ignoramos inicializaciones de variables, etc.
– Inspeccionamos la primera rutina llamada y la examinamos si es importante.
– Inspeccionamos las rutinas llamadas por la primera rutina del programa principal, y examinamos aquéllas que nos parecen importantes.
– Repetimos los pasos 3-4 a lo largo del resto del software.
– Recopilamos esas rutinas “importantes”, que se llaman componentes funcionales.
– Asignamos significado a cada componente funcional, esto es (a) explicamos qué hace cada componente funcional en el conjunto del sistema y (b) explicamos qué hace el sistema a partir de los diferentes componentes funcionales.
A la hora de encontrar los componentes funcionales hay que tener en cuenta que los módulos suelen estar ocupados por componentes funcionales. Además, suele haber componentes funcionales cerca de grandes zonas de comentarios y los identificadores de los componentes funcionales suelen ser largos y formados por palabras entendibles.
Una vez encontrados los posibles componentes funcionales, conviene repasar la lista teniendo en cuenta que un componente es funcional cuando Un componente es funcional cuando su ausencia impide seriamente el funcionamiento de la aplicación, dificulta la legibilidad del código, impide la comprensión de todo o de otro componente funcional o cuando hace caer a niveles muy bajos la calidad, fiabilidad, mantenibilidad, etc.
Vamos a ver cómo a partir de un código java cómo se puede realizar Ingeniería Inversa de Procesos. Tenemos dos clases (Persona y Trabajador)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
class Persona {
protected String nombre;
protected int edad;
protected int seguroSocial;
protected String licenciaConducir;
public Persona(String nom, int ed, int seg, String lic) {
set(nom, ed); seguroSocial = seg; licenciaConducir = lic; }
public Persona() {
Persona(null, 0, 0, null); }
public int setNombre(String nom) {
nombre = nom; return 1; }
public int setEdad(int ed) {
edad = ed; return 1; }
public void set(String nom, int ed) {
setNombre(nom); setEdad(ed); }
public void set(int ed, String nom) {
setNombre(nom); setEdad(ed); }
<b>}</b>
<b>class Trabajador extends Persona {</b>
private String empresa;
private int salario;
public Trabajador(String emp, int sal) {
empresa = emp; salario = sal; }
public Trabajador() {
this(null,0); }
public int setEmpresa String emp) {
empresa = emp; return 1; }
public int setSalario(int sal) {
salario = sal; return 1; }
public void set(String emp, int sal) {
setEmpresa(emp); setSalario(sal); }
public void set(int sal, String emp) {
setEmpresa(emp); setSalario(sal); }
}
|
3- Ingeniería inversa de interfaces de usuario:
Las IGUs sofisticadas se van volviendo de rigor para los productos basados en computadoras y para los sistemas de todo tipo. Por tanto el nuevo desarrollo de interfaces de usuario ha pasado a ser uno de los tipos más comunes de las actividades de reingeniería. Ahora bien, antes de que se pueda reconstruir una interfaz de usuario, deberá tener lugar una actividad de ingeniería inversa.
¿Cómo puedo entender el funcionamiento de la interfaz de usuario existente?
Para comprender totalmente una interfaz de usuario ya existente (IU), es preciso especificar la estructura y comportamiento de la interfaz. Se sugieren tres preguntas básicas a las cuales hay que responder cuando comienza la ingeniería inversa de la IU:
– ¿Cuáles son las acciones básicas que deberá procesar la interfaz, por ejemplo, acciones de teclado y clics de ratón?
– ¿Cuál es la descripción compacta de la respuesta de comportamiento del sistema a estas acciones?
– ¿Qué queremos decir con «sustitución», o más exactamente, qué concepto de equivalencia de interfaces es relevante en este caso?
La notación de modelado de comportamiento puede proporcionar una forma de desarrollar las respuestas de las dos primeras preguntas indicadas anteriormente.
Gran parte de la información necesaria para crear un modelo de comportamiento se puede obtener mediante la observación de la manifestación extrema de la interfaz existente. Ahora bien, es preciso extraer del código la información adicional necesaria para crear el modelo de comportamiento.
Es importante indicar que una IGU de sustitución puede que no refleje la interfaz antigua de forma exacta (de hecho, puede ser totalmente diferente). Con frecuencia, merece la pena desarrollar metáforas de interacción nuevas. Por ejemplo, una solicitud de IU antigua en la que un usuario proporcione un superior (del 1 a 10) para encoger o agrandar una imagen gráfica. Es posible que una IGU diseñada utilice una barra de imágenes y un ratón para realizar la misma función.
Herramientas para la Ingeniería Inversa del Software
Los Depuradores
Un depurador es un programa que se utiliza para controlar otros programas. Permite avanzar paso a paso por el código, rastrear fallos, establecer puntos de control y observar las variables y el estado de la memoria en un momento dado del programa que se esté depurando. Los depuradores son muy valiosos a la hora de determinar el flujo lógico del programa.
Un punto de ruptura (breakpoint) es una instrucción al depurador que permite parar la ejecución del programa cuando cierta condición se cumpla. Por ejemplo, cuando un programa accede a cierta variable, o llama a cierta función de la API, el depurador puede parar la ejecución del programa.
Algunos de los depuradores más conocidos son:
OllyDbg → es un potente depurador con un motor de ensamblado y desensamblado integrado. Tiene numerosas otras características incluyendo un precio de 0 $. Muy útil para parcheado, desensamblado y depuración.
WinDBG → es una pieza de software gratuita de Microsoft que puede ser usada para depuración local en modo usuario, o incluso depuración remota en modo kernel.
Las Herramientas de Inyección de Fallos
Las herramientas que pueden proporcionar entradas malformadas con formato inadecuado a procesos del software objetivo para provocar errores son una clase de herramientas de inserción de fallos. Los errores del programa pueden ser analizados para determinar si los errores existen en el software objetivo. Algunos fallos tienen implicaciones en la seguridad, como los fallos que permiten un acceso directo del asaltante al ordenador principal o red. Hay herramientas de inyección de fallos basados en el anfitrión que funcionan como depuradores y pueden alterar las condiciones del programa para observar los resultados y también están los inyectores basados en redes que manipulan el tráfico de la red para determinar el efecto en el aparato receptor.
Los Desensambladores
Se trata de una herramienta que convierte código máquina en lenguaje ensamblador. El lenguaje ensamblador es una forma legible para los humanos del código máquina. Los desensambladores revelan que instrucciones máquinas son usadas en el código. El código máquina normalmente es específico para una arquitectura dada del hardware. De forma que los desensambladores son escritor expresamente para la arquitectura del hardware del software a desensamblar.
Algunos ejemplos de desensambladores son:
IDA Pro → es un desensamblador profesional extremadamente potente. La parte mala es su elevado precio.
PE Explorer → es un desensamblador que “se centra en facilidad de uso, claridad y navegación”. No es tan completo como IDA Pro, pero tiene un precio más bajo.
IDA Pro Freeware 4.1 → se comporta casi como IDA Pro, pero solo desensambla código para procesadores Intel x86 y solo funciona en Windows.
Bastard Disassembler → es un potente y programable desensamblador para Linux y FreeBSD.
Ciasdis → esta herramienta basada en Forth permite construir conocimiento sobre un cuerpo de código de manera interactiva e incremental. Es único en que todo el código desensamblado puede ser re-ensamblado exactamente al mismo código.
Los compiladores Inversos o Decompiladores
Un decompilador es una herramienta que transforma código en ensamblador o código máquina en código fuente en lenguaje de alto nivel. También existen decompiladores que transforman lenguaje intermedio en código fuente en lenguaje de alto nivel. Estas herramientas son sumamente útiles para determinar la lógica a nivel superior como bucles o declaraciones if-then de los programas que son decompilados. Los decompiladores son parecidos a los desensambladores pero llevan el proceso un importante paso más allá.
Algunos decompiladores pueden ser:
DCC Decompiler → es una excelente perspectiva teórica a la descompilación, pero el descompilador sólo soporta programas MSDOS.
Boomerang Decompiler Project → es un intento de construir un potente descompilador para varias máquinas y lenguajes.
Reverse Engineering Compiler (REC) → es un potente “descompilador” que descompila código ensamblador a una representación del código semejante a C. El código está a medio camino entre ensamblador y C, pero es mucho más legible que el ensamblador puro.
Las Herramientas CASE
Las herramientas de ingeniería de sistemas asistida por ordenador (Computer-Aided Systems Engineering – CASE) aplican la tecnología informática a las actividades, las técnicas y las metodologías propias de desarrollo de sistemas para automatizar o apoyar una o más fases del ciclo de vida del desarrollo de sistemas. En el caso de la ingeniería inversa generalmente este tipo de herramientas suelen englobar una o más de las anteriores junto con otras que mejoran el rendimiento y la eficiencia.
Conclusión
La ingeniería inversa se denomina así porque avanza en dirección opuesta a las tareas habituales de ingeniería, que consisten en utilizar datos técnicos para elaborar un producto determinado. En general, si el producto u otro material que fue sometido a la ingeniería inversa fue obtenido en forma apropiada, entonces el proceso es legítimo y legal. De la misma forma, pueden fabricarse y distribuirse, legalmente, los productos genéricos creados a partir de la información obtenida de la ingeniería inversa, como es el caso de algunos proyectos de Software libre ampliamente conocidos.
La ingeniería inversa es un método de resolución. Aplicar ingeniería inversa a algo supone profundizar en el estudio de su funcionamiento, hasta el punto de que podamos llegar a entender, modificar y mejorar dicho modo de funcionamiento.
Ingeniería Inversa
 Aeropuerto de Ibiza. Salinas al fondo.
Aeropuerto de Ibiza. Salinas al fondo. Salinas de Ibiza
Salinas de Ibiza
 Campos de arroz
Campos de arroz Fortaleza de Isabel II en La Mola, Mahón, Menorca.
Fortaleza de Isabel II en La Mola, Mahón, Menorca. Tuneladora española Bertha. La más grande del mundo construída por ACS.
Tuneladora española Bertha. La más grande del mundo construída por ACS. Tuneladora Miñoca trabajando ya hace 3 años.
Tuneladora Miñoca trabajando ya hace 3 años. Tuneladora Lebre
Tuneladora Lebre Tuneladora TBM de FCC lleva perforados 914 kms, entre La Mancha, Valencia y Murcia.
Tuneladora TBM de FCC lleva perforados 914 kms, entre La Mancha, Valencia y Murcia. Tren bala supersónico de Elon Musk.
Tren bala supersónico de Elon Musk.







 Taladros para mí, pero no para ti: la OTAN lanza juegos de guerra cerca de la frontera rusa
Taladros para mí, pero no para ti: la OTAN lanza juegos de guerra cerca de la frontera rusa







